GRPO
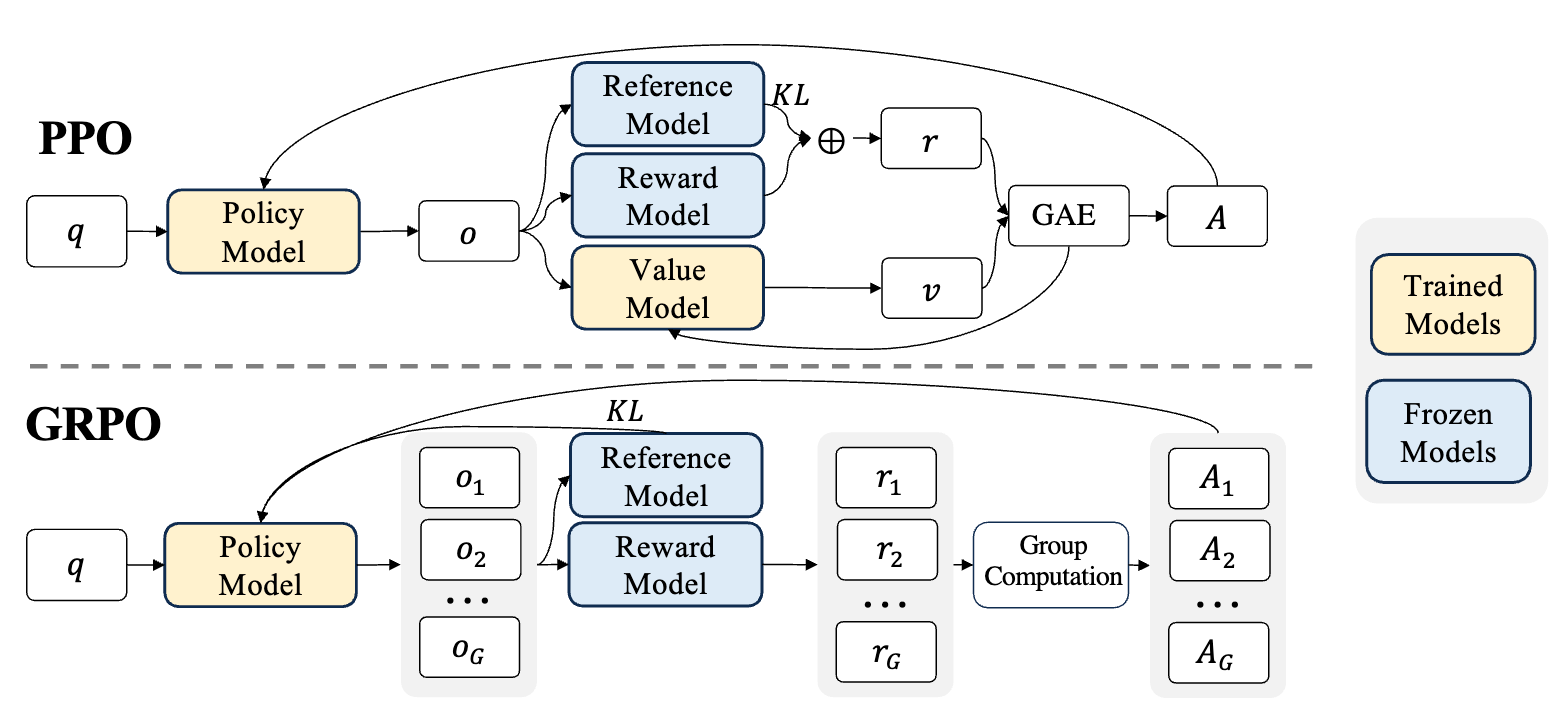
GRPO(Group Relative Policy Optimization)는 DeepSeek에서 2024년 발표한 논문 DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models에서 소개된 LLM 강화학습 방법입니다. SFT(Supervised Fine-Tuning)를 마친 언어 모델의 수학 추론 능력을 더 끌어올리기 위해 사용되며, PPO(Proximal Policy Optimization)를 LLM 학습 상황에 맞게 단순화한 방법이라고 볼 수 있습니다.
핵심 아이디어는 크리틱 또는 가치 함수 모델을 따로 학습하지 않는 것입니다. 대신 같은 질문에 대해 여러 개의 답변을 생성하고, 그 답변들의 보상을 서로 비교해서 기준선(baseline)을 만듭니다. 이렇게 하면 PPO에서 필요했던 별도의 가치 모델을 줄일 수 있어 메모리와 계산 비용이 낮아집니다.
PPO에서 GRPO로
PPO는 액터-크리틱(actor-critic) 방식의 강화학습 알고리즘입니다. LLM을 PPO로 미세조정할 때는 현재 정책 모델 가 이전 정책 모델 에서 너무 멀리 벗어나지 않도록 클리핑을 걸어 다음과 같은 대리 목적 함수를 최대화합니다.
여기서 비율 는 다음과 같습니다.
는 질문, 는 생성된 답변, 는 시간 에서의 어드밴티지입니다. PPO에서는 보상과 학습된 가치 함수 를 이용해 GAE(Generalized Advantage Estimation)로 를 계산합니다.
LLM 강화학습에서는 보상 모델의 과최적화를 막기 위해 보상에 기준 모델(reference model)과의 KL 페널티를 더하는 방식이 흔히 사용됩니다.
여기서 는 보상 모델, 는 기준 정책이며 보통 초기 SFT 모델을 사용합니다. 는 KL 페널티의 강도를 조절하는 계수입니다.
문제는 PPO의 가치 함수 모델이 보통 정책 모델과 비슷한 크기의 별도 모델이라는 점입니다. LLM에서는 이 추가 모델이 메모리와 계산량을 크게 늘립니다. 또 보상 모델이 보통 답변의 마지막 토큰에만 점수를 주기 때문에, 모든 토큰 위치에서 정확한 가치 함수를 학습하는 일도 쉽지 않습니다.
GRPO의 핵심 아이디어
GRPO는 가치 함수 모델을 없애고, 같은 질문에 대해 생성한 답변 그룹의 평균 보상을 기준선으로 사용합니다. 질문 하나에 대해 이전 정책 에서 개의 답변을 샘플링합니다.
각 답변의 보상을 계산한 뒤, 그룹 안에서 상대적으로 좋은 답변은 양의 어드밴티지를 받고 상대적으로 나쁜 답변은 음의 어드밴티지를 받습니다. 따라서 모델은 절대 점수 하나에만 의존하지 않고, 같은 문제에 대해 생성된 후보 답변들 사이의 상대적 품질을 기준으로 업데이트됩니다.
GRPO의 목적 함수는 PPO의 클리핑 구조를 유지하면서, 어드밴티지를 그룹 상대 보상으로 계산하고 KL 정규화 항을 목적 함수에 직접 넣습니다.
여기서
이고, 는 같은 질문에서 나온 답변 그룹 내부의 상대 보상으로 계산한 어드밴티지입니다.
논문에서는 KL 항을 다음 추정량으로 계산합니다.
이 방식은 양수가 보장되는 KL 추정량입니다. GRPO는 KL 페널티를 보상에 섞지 않고 목적 함수에 직접 더하므로, 그룹 상대 어드밴티지 계산을 더 단순하게 유지할 수 있습니다.
결과 감독 GRPO
Outcome supervision은 답변 전체가 끝난 뒤 하나의 보상만 주는 방식입니다. 각 질문 에 대해 개의 답변을 생성하고, 보상 모델로 각 답변의 점수 를 얻습니다.
그다음 그룹 안에서 평균을 빼고 표준편차로 나누어 보상을 정규화합니다.
결과 감독에서는 답변 에 속한 모든 토큰의 어드밴티지를 같은 값으로 둡니다.
즉 답변 전체가 좋게 평가되면 그 답변을 구성한 모든 토큰의 선택 확률을 높이고, 나쁘게 평가되면 모든 토큰의 선택 확률을 낮추는 방향으로 학습합니다.
과정 감독 GRPO
Process supervision은 답변 전체가 아니라 풀이 과정의 각 단계마다 보상을 주는 방식입니다. 수학 문제처럼 여러 추론 단계를 거치는 작업에서는 마지막 정답만 보는 것보다 중간 풀이 단계까지 평가하는 편이 더 촘촘한 학습 신호를 줄 수 있습니다.
각 답변 가 개의 추론 단계로 구성되어 있고, 가 번째 단계의 마지막 토큰 위치라고 하겠습니다. 과정 보상 모델은 각 단계 끝에서 보상을 계산합니다.
이 보상들도 그룹 전체의 평균과 표준편차로 정규화합니다.
각 토큰의 어드밴티지는 그 토큰 이후에 남아 있는 단계 보상들의 합으로 계산합니다.
따라서 특정 토큰 선택이 이후의 좋은 풀이 단계들로 이어졌다면 양의 신호를 더 많이 받고, 이후 단계들이 나쁘게 평가되면 음의 신호를 받게 됩니다.
반복적 GRPO
강화학습이 진행되면 정책 모델이 점점 바뀌기 때문에, 처음 학습한 보상 모델만으로는 현재 정책을 충분히 잘 감독하지 못할 수 있습니다. 이를 해결하기 위해 논문에서는 iterative RL with GRPO도 다룹니다.
반복적 GRPO의 흐름은 다음과 같습니다.
- 현재 정책 모델을 기준 모델로 둡니다.
- 작업 프롬프트 배치를 샘플링합니다.
- 각 질문에 대해 현재 이전 정책에서 개의 답변을 생성합니다.
- 보상 모델로 각 답변의 보상을 계산합니다.
- 그룹 상대 어드밴티지를 계산합니다.
- GRPO 목적 함수를 최대화하도록 정책 모델을 업데이트합니다.
- 정책 모델의 샘플링 결과로 보상 모델 학습 데이터를 새로 만들고, 과거 데이터 일부를 섞는 replay 방식으로 보상 모델을 계속 학습합니다.
논문에서는 과거 데이터의 10%를 replay에 포함한다고 설명합니다. 이렇게 하면 정책 모델과 보상 모델이 함께 최신 분포를 따라가도록 만들 수 있습니다.
PPO와 GRPO 비교
| 항목 | PPO | GRPO |
|---|---|---|
| 기준선 | 학습된 가치 함수 | 같은 질문의 답변 그룹 평균 보상 |
| 추가 모델 | 가치 모델 필요 | 가치 모델 생략 |
| 어드밴티지 | GAE로 계산 | 그룹 내부 상대 보상으로 계산 |
| KL 제어 | 보상에 KL 페널티를 추가 | 목적 함수에 KL 항을 직접 추가 |
| LLM 학습 비용 | 정책 모델, 보상 모델, 가치 모델이 필요해 비용이 큼 | 가치 모델을 제거해 메모리와 계산량을 줄임 |
GRPO의 중요한 관점은 "좋은 답변인지"를 절대적으로만 보지 않고, "같은 질문에서 나온 다른 답변들보다 좋은지"를 학습 신호로 사용한다는 점입니다. 보상 모델 자체도 보통 같은 질문에 대한 답변 비교 데이터로 학습되므로, 그룹 상대 방식은 LLM 선호 학습의 데이터 구조와도 잘 맞습니다.