
AI 모델도 수출통제 대상 되나…미국 정부와 Anthropic 충돌
미국 정부가 Anthropic의 최신 AI 모델 Fable 5와 Mythos 5에 대한 접근을 제한
AI 모델도 수출통제 대상 되나…미국 정부와 Anthropic 충돌
미국 정부가 Anthropic의 최신 AI 모델 Fable 5와 Mythos 5에 대한 접근을 제한

Anthropic, 새 AI 모델 ‘Claude Fable 5’ 공개…더 어려운 일을 맡기는 모델로 확장
길고 복잡한 다단계 협업 작업을 오래 붙잡고 처리하도록 설계된 고성능 AI 모델
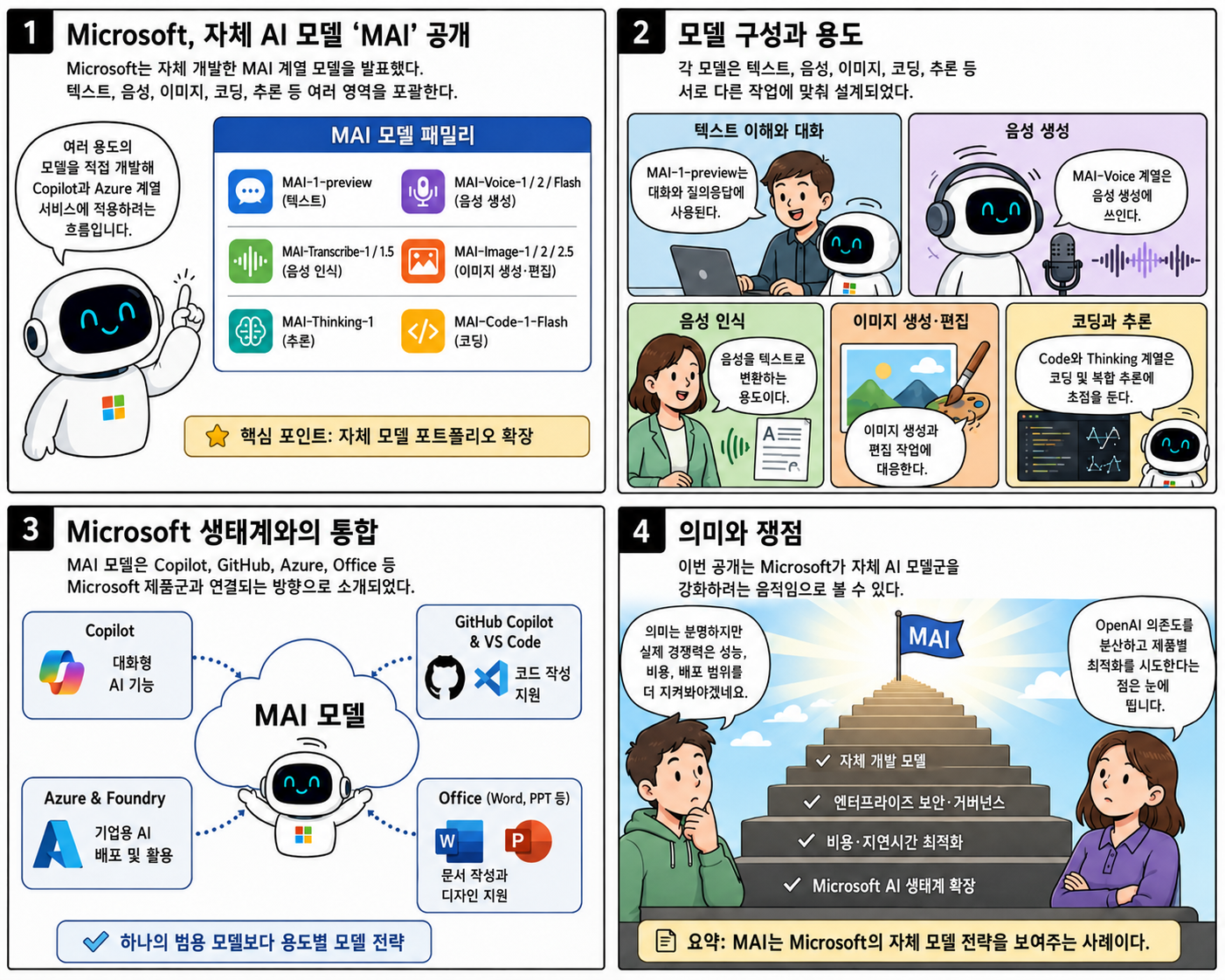
Microsoft, 독자 AI 모델 ‘MAI’ 발표
텍스트·음성·이미지·코딩·추론 등 5개 핵심 영역의 특화 모델을 동시에 공개
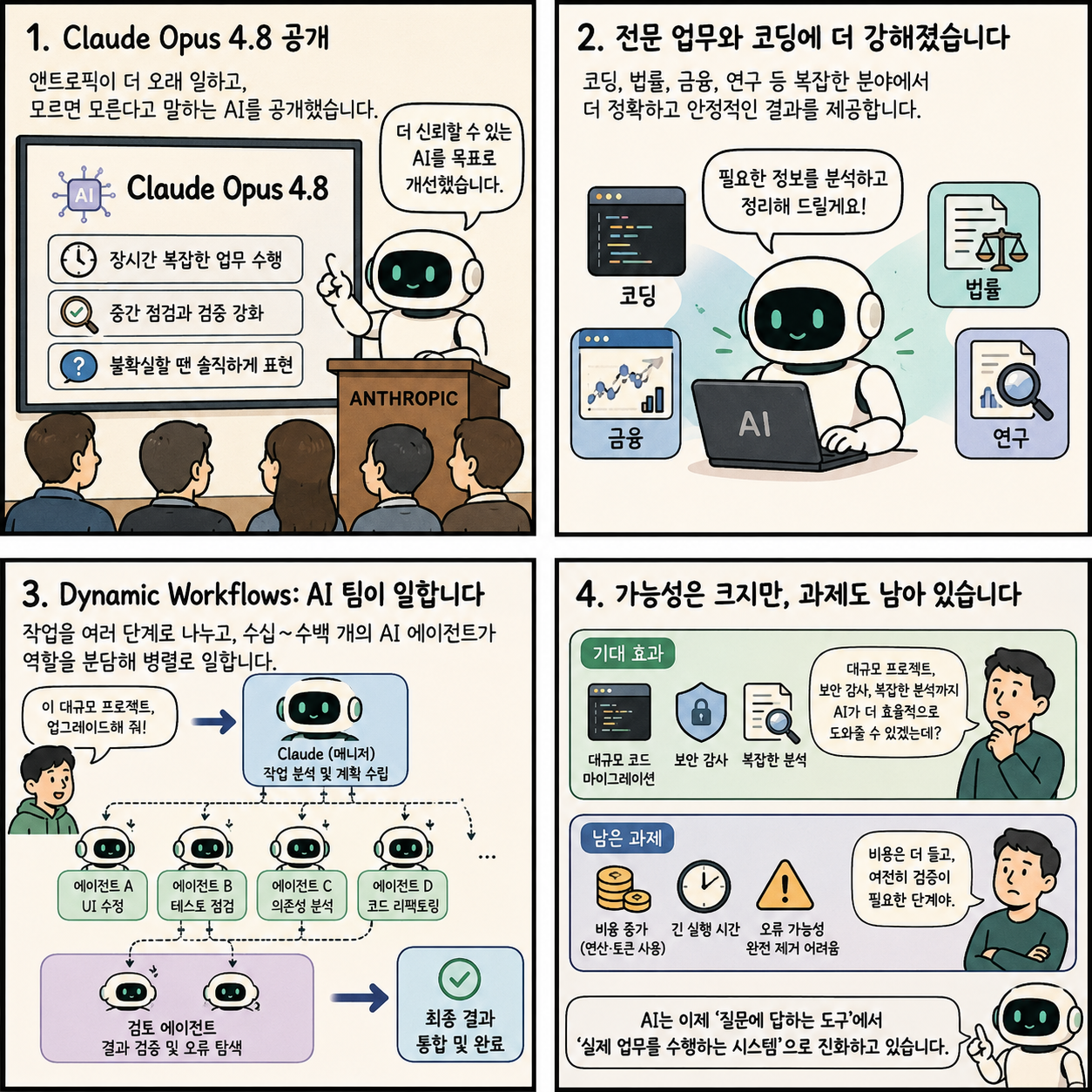
앤트로픽, Claude Opus 4.8 공개… AI의 성능 경쟁에서 ‘업무 수행’ 경쟁으로
Claude Opus 4.8과 Dynamic Workflows는 AI의 경쟁 무대를 ‘더 똑똑한 답변’에서 ‘더 복잡한 업무 수행’으로 옮기고 있습니다.
구글, ‘Antigravity 2.0’ 공개
구글이 AI 에이전트 중심 개발 플랫폼 ‘Antigravity 2.0’을 공개했습니다

“실행 파일만 보고 프로그램 복원하라”… 메타가 공개한 AI 코딩 벤치마크 ‘ProgramBench’
메타는 AI가 단순 코드 생성 수준을 넘어 실제 소프트웨어를 얼마나 이해하고 재구성할 수 있는지를 평가하는 새로운 벤치마크 ProgramBench를 공개했다.