결측치 처리
- 결측치: 데이터셋에서 누락된 값 또는 값이 기록되지 않은 경우
- 주요 원인
- 데이터 수집 오류: 데이터 입력 실수, 기기 오작동이나 데이터 전송 오류
- 의도적 미응답: 설문 등에서 민감한 질문이나 답변하기 까다로운 질문
- 데이터 손실: 데이터베이스 손상, 파일 손실, 시스템 충돌, 네트워크 문제
- 불완전한 데이터 소스: 데이터가 일부만 제공되거나 누락된 경우
결측치의 종류
- MCAR(Missing Completely at Random)
- 결측치가 완전히 무작위로 발생하며, 다른 변수들과 상관관계가 없음
- 예: 설문 조사에서 무작위로 몇 명이 응답하지 않은 경우
- 큰 문제는 아니지만 MCAR은 드묾
- MAR(Missing at Random)
- 결측치가 다른 관측 가능한 변수와 관련이 있지만, 해당 변수와는 무관
- 예: 남성 응답자들이 특정 질문에 응답하지 않은 경우, 성별은 관찰됨
- 어느 정도 대응 가능하며, 일반적으로 결측치에 대해 MAR을 가정하고 대응
- MNAR(Missing Not at Random)
- 결측치가 해당 변수와 관련이 있으며, 무작위로 발생하지 않음
- 예: 소득이 낮은 사람들이 소득 질문에 응답하지 않는 경우
- 대응이 까다로움
결측치 대응 방법
- 삭제(Deletion): 결측치가 있는 데이터를 삭제하고 분석
- 대체(Imputation): 결측치를 다른 값으로 대체
- 모형 기반 접근: 결측치에 영향을 받지 않는 모형 사용
- 결측치 자체를 하나의 특징으로 사용: 특수한 경우에 사용
삭제의 방법
- 리스트 삭제(Listwise Deletion)
- 결측치가 있는 전체 행을 삭제
- 간단하고 구현이 용이하지만, 많은 데이터 손실
- MCAR일 때만 유효
- 페어와이즈 삭제(Pairwise Deletion)
- 분석에 필요한 변수에만 결측치가 있는 행을 삭제
- 데이터 손실 최소화
- 각각의 분석이 서로 다른 부분집합에 대해 이뤄지기 때문에 결과 일관성에 문제가 생길 수 있음
- 예: 상관행렬이 양의 정부호(positive definite)가 아닐 수 있음
실습: 결측치 만들기
import pandas as pd
df = pd.read_excel('car.xlsx')
mileage 열에서 10%의 데이터를 무작위 결측치로 만들기
import numpy as np
np.random.seed(42)
miss_prob = 0.1
df_miss = df.copy()
df_miss['mileage'] = df_miss['mileage'].apply(
lambda x: np.nan if np.random.rand() < miss_prob else x
)
유사 난수
- 대부분의 컴퓨터는 결정론적(deterministic)으로 작동하여 난수(random number)를 생성할 수 없음
- 아주 긴 주기의 수열을 만들어 유사 난수로 사용
- 간단한 알고리즘은 씨앗값으로부터 일정 항 이후부터 사용하는 방식
xk+1=(231−1)xkmod75
- 보통 씨앗값은 현재 시각으로 결정
- 같은 결과를 재현하려고 할 때는 씨앗값을 고정하여 동일한 유사 난수를 생성
코드 설명
df_miss['mileage'].apply()
apply 함수는 Pandas 시리즈(열)의 각 원소에 특정 함수를 적용하는 메소드df_miss['mileage'] 열의 각 원소에 대해 지정된 lambda 함수를 적용
lambda x:
lambda 함수는 익명 함수- 예:
lambda x: x + 1은 입력 x에 1을 더하는 함수
- 여기서는
mileage 열의 각 개별 값이 x로 전달됨
np.nan if np.random.rand() < miss_prob else x
- 삼항 연산자: 참일 경우 값
if 조건 else 거짓일 경우 값
np.random.rand()는 0과 1 사이의 임의의 실수를 생성- 이 값이
miss_prob보다 작으면 np.nan을 반환하여 결측치로 만듦
- 조건이 거짓이면 원래 값
x를 그대로 반환
리스트 삭제
df_miss[df_miss['mileage'].isnull()]
df_miss[df_miss['mileage'].notnull()]
평균과 표준편차
df_miss['mileage'].mean()
- 기본적으로 결측치는 삭제하고 평균냄(
skipna=True)
df_miss['mileage'].mean(skipna=False)
df['mileage'].std()
df_miss['mileage'].std()
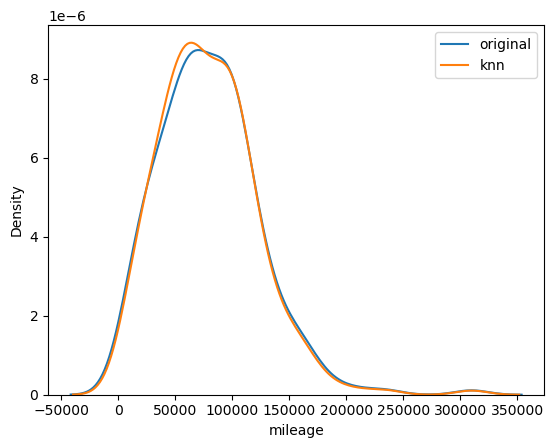
분포 시각화
import seaborn as sns
import matplotlib.pyplot as plt
sns.kdeplot(df['mileage'], label='original')
sns.kdeplot(df_miss['mileage'], label='missing')
plt.legend()
대체의 방법
- 평균/중앙값 또는 최빈값으로 대체
- 장점: 간단하고 빠름
- 단점: 데이터 변동성 감소, 편향 발생 가능
- 예측 대체
- 회귀 모형이나 KNN을 사용하여 결측치를 예측하여 대체
- 장점: 보다 정확한 대체
- 단점: 데이터 변동성 감소
- 다중 대체(Multiple Imputation)
- 결측치를 여러 번 대체하고, 여러 대체 결과를 결합하여 불확실성을 반영
- 장점: 불확실성 반영, 보다 정확한 대체
- 단점: 복잡도 증가, 계산 비용 증가
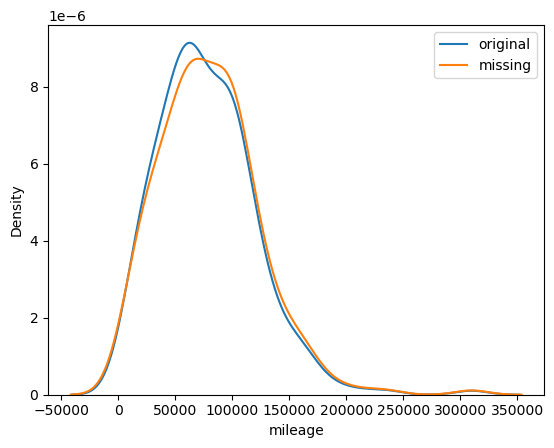
평균으로 대체
m = df_miss['mileage'].mean()
impute_mean = df_miss['mileage'].fillna(m)
impute_mean.mean()
impute_mean.std()
sns.kdeplot(df['mileage'], label='original')
sns.kdeplot(impute_mean, label='mean')
plt.legend()
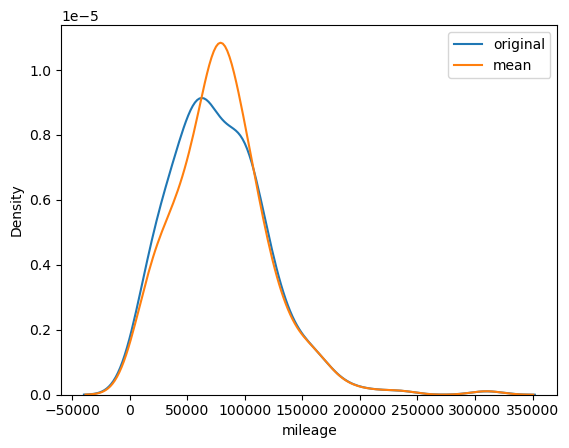
예측 대체
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=2, weights="uniform")
X = imputer.fit_transform(df_miss[['mileage', 'price', 'year']])
impute_knn = X[:, 0]
impute_knn.mean()
impute_knn.std()
sns.kdeplot(df_miss['mileage'], label='original')
sns.kdeplot(impute_knn, label='knn')
plt.legend()